不是简单总结,而是把阅读与设计过程变成可复用知识。
ThinkLens 贴近真实阅读场景:边看原文、边追问、边沉淀,适合需要反复消化复杂资料的人。
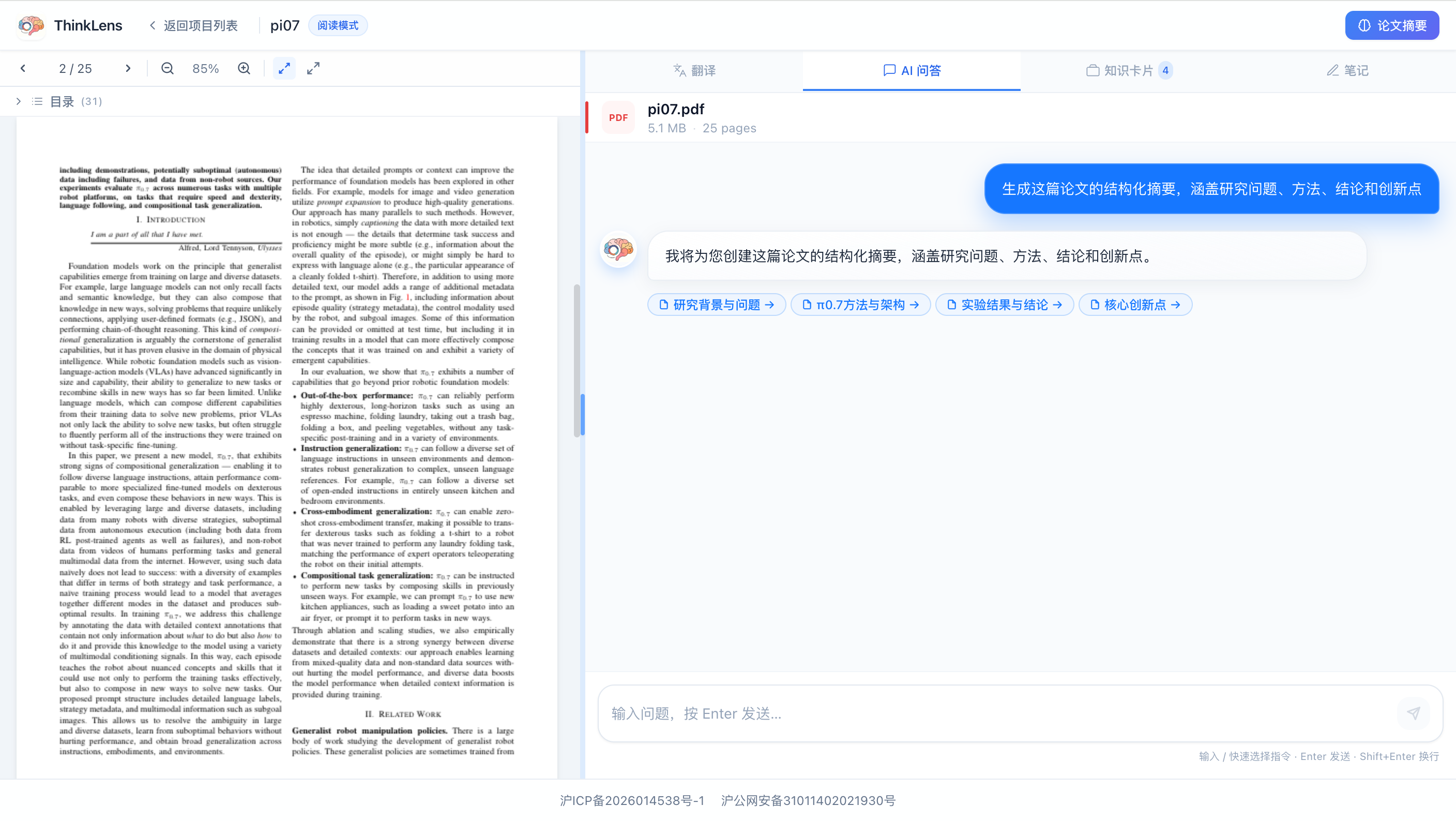
围绕文档持续追问
AI 基于当前资料回答问题,支持继续追问、拆解段落、比较观点和生成下一步问题。
自动生成知识卡片
从长文档中提炼概念、结论、证据和行动项,让信息从一次性阅读沉淀为项目知识库。
PDF 中文翻译
阅读外文论文、说明书和报告时可按页翻译,支持更自然的中文表达和专业术语保留。
原文引用与上下文
回答可以回到对应文档段落,减少凭空概括,让你更容易判断信息是否可靠。
多资料项目管理
把 PDF、文本、代码和笔记放进同一个项目,围绕主题建立连续的知识脉络。
导出与分享
将知识页导出为 HTML 或 PDF,也可分享整个知识页或单张卡片链接给他人查看。
澄清问答卡片
当需求过宽或信息不明确时,AI 会先提出针对性问题,确认方向后再生成知识页。
知识图谱与关系图
需要梳理概念关系、流程或思维导图时,可生成可查看、可调整并导出为图片的关系图页面。
为需要认真读资料的人设计。
官网内容围绕真实使用者展开,而不是只堆功能名。
学生与研究者
阅读论文、教材和参考资料,快速梳理论点、方法、实验结论和后续问题。
行业分析
拆解研报、政策、财报和竞品资料,把关键信息沉淀为可复盘的判断依据。
产品与研发团队
理解需求文档、技术方案和接口说明,通过 AI 辅助阅读和结构化知识提取,减少信息传递中的遗漏和误读。
法务与咨询
梳理合同、尽调材料和长篇报告中的风险点、定义条款与待确认事项。
三步完成从阅读到知识沉淀。
ThinkLens 的核心不是替你看一眼文档,而是把文档变成可以继续追问、整理和分享的知识资产。
上传资料
创建项目后上传 PDF、文本或代码文件。你可以把同一主题的多份资料放在一起管理。
边读边问
在阅读器旁直接提问,让 AI 解释概念、总结章节、提取证据或翻译当前页面。
沉淀知识
把 AI 生成的卡片保存为知识页,后续可回看、补充、导出并分享给团队。
先试用,再按资料规模升级。
当前应用支持游客体验、Free/Plus/Pro 三档会员和微信支付升级,能力与额度以应用内为准。
上线前用户最关心的事。
ThinkLens 支持哪些文档格式?
当前应用支持 PDF、Markdown、TXT、常见代码文件、Excel 和 CSV,也支持直接粘贴文本创建项目。
AI 回答会引用原文吗?
产品设计上会尽量保留文档上下文和页码线索,方便你回到原文核对,而不是只看一段孤立总结。
适合读外文论文或英文资料吗?
适合。你可以在 PDF 阅读过程中逐页翻译成中文,也可以要求 AI 解释术语、改写为更自然的中文。
文档内容安全吗?
文档会用于你授权的分析、翻译、分享和导出流程。服务端包含鉴权、限流、上传限制、HTML 清理和公开链接撤销机制,但 AI 输出仍需你自行核验。
可以给团队使用吗?
当前正式提供的是个人账号、公开分享链接和单卡片分享。团队空间或私有化部署不应视为已上线能力。